Lista frekwencyjna wypowiedzeń polskich
Robert Wołosz
Terminologia
Publikowana lista powstała w wyniku segmentacji tekstów zapisanych w języku polskich, które oczywiście mogły zawierać wyrazy, zwroty a nawet całe zdania zapisane w innym języku.
Segmentacja przeprowadzona została automatycznie na podstawie przyjętych założeń dotyczących początku i końca wypowiedzenia. Założenia te nie zapewniają absolutnej poprawności segmentacji, ale w przypadku zbioru tekstów liczącego ponad 550 milionów wypowiedzeń przyjęte rozwiązanie wydaje się uzasadnione.
Za wypowiedzenie traktuję fragment tekstu, którego początek zapisany jest wielką literą, cyfrą lub myślnikiem i zakończony znakiem (lub serią znaków) przestankowym, który traktowany jest jako wyznacznik końca wypowiedzenia, po którym następuje wielka litera, cyfra lub myślnik (lub koniec tekstu).
Jeśli analizowany plik zaczynałby się od wyrazu zapisanego małą literą, to ten jego fragment, który nie zawiera cyfry, myślnika lub wyrazu zapisanego wielką literą, następujących po wyznaczniku końca wypowiedzenia, jest pomijany z dalszej analizy.
Wyznaczniki końca wypowiedzenia
Za wyznaczniki końca wypowiedzenia traktuję: kropkę, wykrzyknik, pytajnik, wielokropek i dwukropek. Pojawienie się wśród wymienionych dwukropka może dziwić, ale z analizy tekstów wynika, iż znak ten jest często zapowiedzią pojawienia się nowego wypowiedzenia.
Rozróżniam dwa rodzaje kropki. Jedna traktowana jest jako litera. Dzieje się tak w przypadku skrótów, których jest elementem ortograficznie koniecznym (na przykład przy np.). Wszystkie pozostałe zapisy kropki traktowane są jako wyznaczniki końca wypowiedzenia. Informację o tym, które skróty zapisywane z kropką uwzględniłem w analizie, można znaleźć w załączonym przeze mnie skrypcie Perla cut_nl.pl.
Uwagi techniczne
Przed obliczeniem frekwencji poszczególnych wypowiedzeń poddane są one „czyszczeniu”. Ujednolicone zostają apostrofy; myślniki i łączniki zapisywane są tym samym znakiem (ASCII 45), wprowadza się konsekwentny zapis wielokropka (…), tabulator zastępowany jest spacją, powtarzające się obok siebie spacje zostają zapisane jako spacja pojedyncza. Usuwane są z tekstu nawiasy oraz myślniki rozpoczynające wypowiedzenia.
Nie jest zmieniany zapis liter wielkich na małe (ani małych na wielkie). Powoduje to traktowanie wypowiedzenia „Kocham Cię.” jako różniącego się od wariantu „Kocham cię.”.
Nie usuwam przed przeprowadzeniem obliczeń wyznaczników końca wypowiedzenia. Powoduje to traktowanie na naszej liście jako elementów różnych następujących wypowiedzeń: Tak., Tak?, Tak!, Tak…, Tak?!, Tak…?, Tak?…, Tak:, Tak!… Warto zaznaczyć, że podane dane umożliwiają połączenie tych rekordów w jeden i obliczenie wspólnej frekwencji.
Czy warto badać frekwencję wypowiedzeń?
Na to pytanie nie jest łatwo odpowiedzieć. Niewątpliwie wielu badaczy języka może uznać, iż wypowiedzeń Jan kocha Martę. i Jan kocha Marię. nie warto traktować jako osobne byty (choć dla Marty i Marii może być to nieobojętne). Zapewne nie przez przypadek powstaje wiele prac poświęconych frekwencji liter, fonemów, słów, związków słów (N-gramy), ale brak ich w przypadku zdań.
Założyłem jednak, że badania takie mogą mieć sens. Niewątpliwie warto wykorzystać wiedzę o najczęstszych wypowiedzeniach przy tworzeniu podręczników do nauki języka polskiego jako obcego. Dane te mogą pomóc w badaniach frazeologicznych (paremiologicznych) np. przy ustalaniu zapisu najczęściej używanych wariantów. Wiele mówią też o użytkownikach języka (proponuję poszukać wśród danych wulgaryzmów czy wypowiedzeń odnoszących się do różnych nacji).
Źródła i narzędzia badań
Badanie frekwencji wypowiedzeń możliwe jest, jeśli dysponujemy odpowiednim zbiorem tekstów i narzędziami potrzebnymi do ich analizy.
Zbiór tekstów, podział na podkorpusy
Jest to zbiór tekstów zgromadzonych przeze mnie i wykorzystywany przy różnych pracach językowych. Nie używam słowa korpus, ponieważ zbiór ten nie spełnia wielu wymogów stawianych korpusom naukowym (np. zrównoważenie danych, występowanie pełnych tekstów zamiast próbek itd.). Oczywiście wiele cech gromadzonych przeze mnie tekstów upodabnia je do korpusu: elektroniczna wersja danych, zachowanie informacji o autorach i pochodzeniu tekstów, podział na podzbiory (teksty tłumaczone na polski z języków obcych i teksty tworzone po polsku); artykuły prasowe (dzienniki i czasopisma); książki; napisy filmowe, blogi itd.
Wielkość badanego zbioru mierzona w słowach rozumianych jako ciągi znaków między spacjami (lub znakami o wartości spacji) wynosi ponad 6 miliardów słów. Podzielony został na ponad 550 milionów wypowiedzi. Część wyodrębnionych wypowiedzi nie trafiła do dalszej analizy. Były to np. wypowiedzi liczące więcej niż 1000 znaków oraz takie, które nie zawierały ani jednej litery polskiego alfabetu.
Ponieważ dane o frekwencji względnej, uwzględniające równomierność rozkładu, wydają się ciekawsze od tych odnotowujących frekwencję absolutną, zbiór tekstów podzielony został na trzy grupy. Do grupy pierwszej, najliczniejszej trafiły teksty książek tłumaczonych z języków obcych (ok. 244 milionów wypowiedzeń). Grupa licząca najmniej wypowiedzeń (ok. 132 miliony) zawiera teksty prasowe z dzienników i czasopism. Ostatnia z wyróżnionych grupa zawiera pozostałe teksty (ok. 178 miliony wypowiedzeń). W grupie tej większe bloki stanowią teksty oryginalnych polskich książek (ok. 116 milionów), napisy filmowe (zazwyczaj tłumaczone z języka angielskiego; blisko 36 milionów wypowiedzeń), teksty aktów prawnych i stenogramy z posiedzeń sejmu i senatu (ok. 1,5 miliona wypowiedzeń), blogi, teksty ściągnięte z najróżniejszych stron internetowych (np. zbiory polskiej wersji Wikipedii – ok. 20 milionów wypowiedzi).
Bardzo trudne do uniknięcia jest w tak wielkim zbiorze przypadków dwu- czy wielokrotnego zapisu tych samych tekstów, choć staram się tego unikać. Powodów niezamierzonych powtórzeń jest wiele. Może to być praktykowane (choć często nieuczciwe) publikowanie tych samych tekstów pod różnymi tytułami (dotyczy to głównie tłumaczeń). Zdarza się też, że pewne teksty (np. felietony) pojawiają się najpierw w prasie. Niektóre z nich są przedrukowywane w innych czasopismach, potem trafiają do książek (zbiorów felietonów), a następnie do jakichś antologii itd. Akty prawne też cytowane są w prasie i najróżniejszych wydawnictwach książkowych. Wszystko to powoduje, że pewne wypowiedzenia podawane przeze mnie mają zawyżoną frekwencję.
Tak więc w pewnych przypadkach da się ustalić źródło pochodzenia cytowanych wypowiedzeń, choć zakładałem, że tak nie będzie (pomijam oczywiście powszechnie znane i cytowane przysłowia, skrzydlate słowa itd.).
Niestety wszystkie teksty zbioru zapisane są standardzie Windows-1250, co wpływa na rezultat wykonanych prac. Nie znajdziemy wśród wypowiedzeń wyrazów señor ani wyrażenia à la carte, ponieważ we wspomnianym standardzie brak liter ñ i à.
Narzędzia
Poza standardowym, ogólnie dostępnym oprogramowaniem (np. grep) na potrzeby niniejszej pracy powstało wiele skryptów Perla (autorstwa mojego i Mártona Wołosza) oraz kilka programów komputerowych napisanych w języku C++ (autorstwa Jánosa Wołosza).
Proces badawczy – ekscerpcja danych
Zbiór tekstów (ponad 100 tysięcy plików) podzielony został na wspomniane wcześniej trzy podkorpusy. Następnie wszystkie pliki znajdujące się w nich zostały zapisane z podziałem na wypowiedzenia. Kolejne etapy pracy polegały na czyszczeniu (ujednolicaniu) plików oraz usuwaniu z nich tych fragmentów, które nie spełniały przyjętych założeń (dotyczyło to długości wypowiedzenia mierzonej liczbą znaków oraz znaków pojawiających się na początku i końca wyróżnionych fragmentów).
Następnie wszystkie pliki danego podkorpusu były łączone w jeden plik. Powstałe w ten sposób pliki miały wielkość ok. 18, 13 i 12 GB.
Pliki te były sortowane, aby identycznie zapisane wypowiedzenia pojawiały się bezpośrednio po sobie. Następnie program freqlst_new.exe zliczał identyczne wiersze i informację o ich ilości pozostawiał na końcu wiersza, a powtarzające się, identycznie zapisane wiersze usuwał.
Kolejny krok polegał na usunięciu z plików wszystkich wypowiedzeń, które pojawiły się w nim tylko jeden raz. Zachowane wypowiedzenia zapisywane były już w znacznie mniejszych plikach (640 MB, 502 MB, 337 MB). Warunkiem trafienia wypowiedzenia na listę frekwencyjną było jego dwukrotne pojawienie się w przynajmniej dwóch podkorpusach. Jeśli więc jakieś wypowiedzenie pojawiło się w trzech podkorpusach, ale w każdym z nich tylko jeden raz, nie jest odnotowane. Nie wystarczyła też do pojawienia się na liście dowolnie wysoka frekwencja w jednym podkorpusie, jeśli w dwóch pozostałych wypowiedzenie nie wystąpiło przynajmniej dwa razy.
Połączenie identycznych wypowiedzeń z różnych podkorpusów w jedno wypowiedzenie z informacją o tym, gdzie się pojawiło i ile razy wymagało użycia specjalnego programu. Jak przebiegał ten proces najlepiej wytłumaczyć na konkretnym przykładzie.
W podkorpusie 1. (tłumaczone na język polski wydawnictwa książkowe) wyróżniłem następujące wypowiedzenia zaczynające się od ciągu znaków „Kto rano wstaje”:
Kto rano wstaje temu Pan Bóg daje. 2 1
Kto rano wstaje, temu Pan Bóg daje! 7 1
Kto rano wstaje, temu Pan Bóg daje. 34 1
Kto rano wstaje, temu pan Bóg daje. 5 1
Kto rano wstaje… 14 1
Kto rano wstaje… i tak dalej. 2 1
1 na końcu akapitu wskazuje na podkorpus, a poprzedzająca go liczba określa, ile razy dane wypowiedzenie zostało potwierdzone w tym podkorpusie.
W podkorpusie 2. (oryginalne polskie teksty, inne niż prasowe) wyróżniłem następujące wypowiedzenia zaczynające się od ciągu znaków „Kto rano wstaje”:
Kto rano wstaje i tak dalej. 2 2
Kto rano wstaje temu pan Bóg daje. 2 2
Kto rano wstaje, temu Pan Bóg daje! 5 2
Kto rano wstaje, temu Pan Bóg daje. 46 2
Kto rano wstaje, temu Pan Bóg daje… 3 2
Kto rano wstaje, temu pan Bóg daje. 10 2
Kto rano wstaje, ten leje jak wół na malowane wrota. 2 2
Kto rano wstaje, ten leje jak z cebra. 3 2
Kto rano wstaje… 13 2
W podkorpusie 3. (polskie teksty prasowe) wyróżniłem następujące wypowiedzenia zaczynające się od ciągu znaków „Kto rano wstaje”:
Kto rano wstaje, temu Pan Bóg daje. 5 3
Kto rano wstaje, ten ma szansę zastać maleńką toaletę czystą. 2 3
Kto rano wstaje… 5 3
Wspomniany program łączył te informacje (po wcześniejszym połączeniu plików i ich posortowaniu) i zapisywał dane tak:
Kto rano wstaje i tak dalej. 0 1 2 2 0 3
Kto rano wstaje temu Pan Bóg daje. 2 1 0 2 0 3
Kto rano wstaje temu pan Bóg daje. 0 1 2 2 0 3
Kto rano wstaje, temu Pan Bóg daje! 7 1 5 2 0 3
Kto rano wstaje, temu Pan Bóg daje. 34 1 46 2 5 3
Kto rano wstaje, temu Pan Bóg daje… 0 1 3 2 0 3
Kto rano wstaje, temu pan Bóg daje. 5 1 10 2 0 3
Kto rano wstaje, ten leje jak wół na malowane wrota. 0 1 2 2 0 3
Kto rano wstaje, ten leje jak z cebra. 0 1 3 2 0 3
Kto rano wstaje, ten ma szansę zastać maleńką toaletę czystą. 0 1 0 2 2 3
Kto rano wstaje… 14 1 13 2 5 3
Kto rano wstaje… i tak dalej. 2 1 0 2 0 3
Zapis ten pozwolił automatycznie wyróżnić te cztery wypowiedzenia, które pojawiły się przynajmniej w dwóch podkorpusach (zapisuję je na zielonym tle). One trafiły do dalszej obróbki i pojawiają się na liście frekwencyjnej wypowiedzeń. Wypowiedzenia zapisane na żółtym tle potwierdzone zostały tylko w jednym podkorpusie, dlatego usunięte zostały z kolejnego etapu opracowywanych danych.
Jak widać wpływ na frekwencje może mieć interpunkcja (usunięte wypowiedzenie Kto rano wstaje temu Pan Bóg daje.) i użycie wielkiej i małej litery (Pan Bóg i pan Bóg).
Zapis wyniku badań
Po wybraniu ze zbioru tekstów wypowiedzeń, które spełniały przyjęte założenia (dwukrotne wystąpienie w przynajmniej dwóch podkorpusach) do wykonania pozostało już tylko jedno zadanie: przedstawienie rezultatu badań w postaci listy rangowej.
Najłatwiej zbudować taką listę w oparciu o częstotliwość absolutną, którą otrzymamy sumują wystąpienia danego wypowiedzenia w podkorpusach.
Dla Kto rano wstaje, temu Pan Bóg daje. częstotliwość absolutna wyniosłaby 85 (31 + 46 + 5), a dla Kto rano wstaje, temu pan Bóg daje. 15 (5+10+0).
Informację o częstotliwości absolutnej podaję w pliku zbiorczym (do którego link znajduje się pod niniejszym tekstem).
Badacze zajmujący się frekwencją językową wskazują na to, iż często warto obliczyć częstotliwość względną, która uwzględnia wewnętrzne zróżnicowanie danych. Wyróżniając tylko trzy podkorpusy kierowałem się tym m. in. tym, iż wielkości ich były zbliżone do siebie. Wydzielenie np. podkorpusu napisów filmowych czy encyklopedycznego (Wikipedia) jedność tę by naruszyły.
Obliczenia częstotliwości względnej dokonuje się na podstawie następującego wzoru ogólnego:
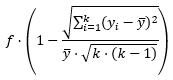
gdzie
k oznacza liczbę podkorpusów (w naszym przypadku k = 3),
m1, m2, …, mk oznaczają liczbę elementów w danym podkorpusie, przy założeniu, że m1 jest zbiorem najliczniejszym (w naszym przypadku m1 = 244259929, m2 = 178200450, m3 = 132198483),
x1, x2, …, xk oznaczają liczbę elementów w danym podkorpusie (np. w przypadku wypowiedzenia Kto rano wstaje, temu Pan Bóg daje. x1 = 34, x2 = 46, x3 = 5),
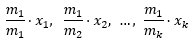
oznacza względną częstotliwość elementu w danym podkorpusie (w naszym przypadku dla wspomnianego wypowiedzenia wartość ta dla podkorpusu 1. to
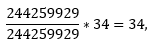
dla podkorpusu 2.:
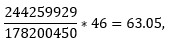
a dla podkorpusu 3.:
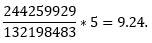
wartości te oznaczam dalej jako: y1, y2, …, yk,
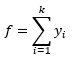
określa względną liczbę wystąpień (w podanym przykładzie wynosi 34 + 63.05 + 9.24 = 106.29),
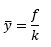
to średnia względnej liczby wystąpień (w podanym przykładzie wynosi 35.43).
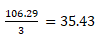
Teraz podany wyżej wzór na obliczenie częstotliwości względnej staje się zrozumiały (w omawianym przykładzie wynosi: 59.64).
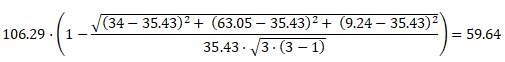
(Sposób obliczania częstotliwości względnej podaję za: Słownik frekwencyjny polszczyzny współczesnej. Kraków, 1990. W omawianym słowniku pięć analizowanych podkorpusów jest identycznej wielkości).
Oto przykład wypowiedzenia o bardzo wysokiej częstotliwości absolutnej, którego rozkład jest bardzo niejednolity: Wstęp wolny. W podkorpusie pierwszym wypowiedzenie to występuje 35 razy, w podkorpusie drugim 78 razy, a w tekstach prasowych (podkorpus trzeci) zaświadczone jest ponad 60 tysięcy jego wystąpień. Gdybyśmy brali pod uwagę częstotliwość absolutną byłoby to 28. najczęstsze wypowiedzenie. Na liście ułożonej wg częstotliwości względnej jest na miejscu 15458.
Struktura pliku zawierającego informację o częstotliwości wypowiedzeń
Każdy akapit (rekord) zawiera 6 pól, które oddzielane są tabulatorem.
Pole pierwsze to graficzna forma wypowiedzenia, np. Kto rano wstaje, temu Pan Bóg daje.
Następne trzy pola są zawsze liczbami całkowitymi i zwierają informację o liczbie wystąpienia wypowiedzenia kolejno w podkorpusie pierwszym drugim i trzecim. Pole piąte zawiera informację o częstotliwości względnej wypowiedzenia, a pole szóste w częstotliwości bezwzględnej.
Wypowiedzenia zapisane są w kolejności od liczby największe do najmniejszej wg częstotliwości względnej. Jeśli podana wartość charakteryzuje więcej niż jedno wypowiedzenie, to wcześniej podawane jest wypowiedzenie o większej częstotliwości bezwzględnej. Porównaj:
To bardzo miłe. 317 484 130 830.0943 931
Nie zawsze tak było. 367 180 174 830.0943 721
W przypadku identycznej wartości pola piątego i szóstego o kolejności decyduje zapis wypowiedzenie (przy czym trzeba zaznaczyć, że Excel nie daje sobie rady z poprawnym zapisem kolejności alfabetycznej tekstu zapisanego po polsku).
Zakończenie
Analiza ponad 550 milionów wypowiedzeń pochodzących z trzech podkorpusów pozwoliła wyróżnić ponad półtora milion takich, które powtarzają się przynajmniej dwa razy w przynajmniej dwóch podkorpusach. Opublikowana lista zawiera jednak tylko te, których częstotliwość absolutna wyniosła przynajmniej 5 (przy zachowaniu warunku pojawienia się w przynajmniej dwóch podkorpusach). Takich wypowiedzeń wyróżniłem niewiele ponad milion. Publikuję je, choć mam świadomość, że naprawdę wiarygodne wyniki osiągnęliśmy w przypadku wypowiedzeń charakteryzujących się największą częstotliwością względną. Wypowiedzeń o częstotliwości względnej ≥ 1000 jest 2754, a o częstotliwości względnej ≥ 500 blisko 6000. W przypadku częstotliwości absolutnej dane te wynoszą: 5130 i 11297.
Wiele z wyekscerpowanych danych jest mało interesująca (a nawet jest wynikiem błędnego podziału tekstu: zob. np. W r.
Jestem jednak przekonany, że nawet w tej formie mogą dostarczyć ciekawych materiałów do dalszych badań (choćby o stylu języka prasy, por. dane ilościowe przy wypowiedzeniach Och?, Jęknęła., Zagrają:, Puchar Świata.).
Literatura
Rudolf, Michał: Metoda automatycznej analizy korpusu tekstów polskich. Pozyskiwanie, wzbogacanie i przetwarzanie informacji lingwistycznych. Warszawa, 2004, Uniwersytet Warszawski.
Kurcz, Ida (et al.): Słownik frekwencyjny polszczyzny współczesnej. I-II. Kraków, Warszawa, 1990, IJP PAN.
15 sierpnia 2022 r., wersja 1.1
A publikáció a lengyel mondatok gyakorisági listáját tartalmazza, oly módon, hogy az adatokat abszolút és súlyozott gyakoriság szerint lehessen rangsorolni. A munka alapját a szerző által összegyűjtött, egyedi eljárással feldolgozott lengyel nyelvű szövegek alkotják, amelyek nagysága kb. 6,5 milliárd szó. Az elért eredmények jól használhatók a lengyel mint idegen nyelv tanításánál, a frazeológiai kutatásokban, stíluselemzések terén, valamint a szövegek digitalizálásából fakadó problémák elemzéséhez. A publikáció a lengyel szövegekben felbukkanó egymillió leggyakoribb mondatot közli. A ranglista elején szereplő mondatok besorolását nagy megbízhatóság jellemzi.